What's coming in Elixir 1.3
I recently gave a talk about Elixir 1.3 in Tokyo, and spoke about the changes, new features, improvements and all the awesome stuff coming in Elixir 1.3. I decided to write this as a blog post, with a little more details, and some links for those who want to check in more details.
Here is a short table of contents:
- Deprecation of imperative assignment
withon steroids- Calendar datatypes
- ExUnit new features
- Access selectors
mix xrefescriptinstallation related tasks- ExUnit diff
makecompiler addition- Changes in
defdelegate Process.sleepaddition- Support of OTP
optionalcallback - New mix tasks
The list is not complete and the order is quite biased, but I think the main changes are here. Of course, you can always check the full changelog.
Deprecation of imperative assignment
I would argue that this is one of the most important changes in 1.3, and will make a lot of projects emit warnings, which is why I brought this up first.
As a lot of you probably already know, from 1.2, conditional variable declaration has been deprecated.
This means that instead of writing something like this
if condition do
n = 1
else
n = 2
end
IO.puts(n)
which will make the compiler explain us that
the variable “n” is unsafe
we should write
n = if condition do
1
else
2
end
IO.puts(n)
I think that this warning is not too surprising, and has a solution that works in every case. For people coming from a Ruby background, Rubocop gave us the same warning by default.
However, in 1.2, we could write the following,
def imperative_duplicate(str, n, opts \\ []) do
if opts[:double] do
n = n * 2
end
String.duplicate(str, n)
end
which is actually quite common.
This will be deprecated from 1.3. This is a little more constraining, and does not have a solution that work for every cases, as the previous warning did. For the above code, we could for example, add a helper as follow:
def imperative_duplicate(str, n, opts \\ []) do
n = double_if_true(n, opts[:double])
String.duplicate(str, n)
end
defp double_if_true(n, true), do: n * 2
defp double_if_true(n, false), do: n
or simply rewrite like this:
def imperative_duplicate(str, n, opts \\ []) do
n = if opts[:double], do: n * 2, else: n
String.duplicate(str, n)
end
Both are a little more verbose, so I would like to discuss why this change has been introduced, and why I think it is a good thing.
Currently, we have basically two scopes rule depending on the special form we use:
with, for and try get their own scope, and do not leak, while case, cond and
receive do not get their own scope.
So when comparing
x = 1
with :ok <- :ok do
x = 2
end
IO.puts(x)
and
x = 1
case :ok do
:ok -> x = 2
end
IO.puts(x)
someone new to Elixir would probably expect both code to output the same thing, but the first case outputs 1 while the second outputs 2.
Although the scoping rules are well documented, I think that having all special forms getting their own scope will make thinks simpler, and this is where we are heading with the deprecation of imperative assignment.
Therefore, hopefully in Elixir 2.0
x = 1
case :ok do
:ok -> x = 2
end
IO.puts(x)
will output 1 and not 2.
Other than simplicity, another advantage mentioned by Jose in the mailing list is making things easier to refactor. Here is the example he gave.
For example, imagine this code:
path = if (file = opts[:file]) && (line = opts[:line]) do relative = Path.relative_to_cwd(file) message = Exception.format_file_line(relative, line) <> " " <> message relative end # ... {path, message}Now imagine we want to move the “if block” to its own function to clean up the implementation:
path = with_file_and_line(message, opts) {path, message} defp with_file_and_line(message, opts) do if (file = opts[:file]) && (line = opts[:line]) do relative = Path.relative_to_cwd(file) message = Exception.format_file_line(relative, line) <> " " <> message relative end endThe refactored version is broken because the “if block” was actually returning two values, the relative path AND the new message. The new message was returned implicitly via the scope which now is broken. In this particular case we get a warning but we may not always.
To sum it up, we will get simpler and more consistent scoping rules at the cost of a little verbosity in some cases. This is in my opinion a very reasonable tradeoff.
For more details, you can take a look at this thread in the mailing list.
with on steroids
In Elixir 1.2, the new special form with was introduced, mainly to make working with nested case easier. The relevant thread from the ML can be found here.
There was however two drawbacks that have been adressed in 1.3.
The first one was when doing some processing on the error case. Here is more or less the example that have been given in the issue tracker for this proposal:
case create_organization(params) do
{:ok, organization} ->
case create_address(organization, params) do
{:ok, address} ->
%{organization | address: address}
{:error, changeset} -> {:error, changeset |> error_string}
end
{:error, changeset} -> {:error, changeset |> error_string}
end
It is easy enough to rewrite the success case with with, but the error case is a bit more tedious as we need to do some processing on the error value.
As of 1.2, this would probably be rewritten in the following way
with {:ok, organization} <- create_organization(params),
{:ok, address} <- create_address(organization, params) do
{:ok, %{organization | address: address}}
end
|> case do
{:ok, organization} -> {:ok, organization}
{:error, changeset} -> {:error, changeset |> error_string}
end
which is a little cleaner but still does not feel very pretty.
This is where with/else comes in.
The else part allows to match on error cases, so the above example can be rewritten as follows.
with {:ok, organization} <- create_organization(params),
{:ok, address} <- create_address(organization, params) do
{:ok, %{organization | address: address}}
else
{:error, changeset} -> {:error, changeset |> error_string}
end
This looks much better, and as we can pattern match on error cases, it is also very easy to change the behavior depending of which clause has fail.
If none of the clause in the else part matches, a WithClauseError will be raised, which is very close to what we already have for try/else.
Another drawback when using with was the impossibility of using guards. There was therefore no easy way to rewrite the following code using with.
case HTTPoison.get(url) do
{:ok, %Response{status_code: code, body: body}} when code in 200..299 ->
case Poison.decode(body) do
{:ok, data} -> data
_ -> :error
end
_ -> :error
end
With Elixir 1.3, we will be able to use guards in with, so the above code can be rewritten as follow.
with {:ok, %Response{status_code: code, body: body}}
when code in 200..299 <- HTTPoison.get(url),
{:ok, data} <- Poison.decode(body) do
data
else
_ -> :error
end
You can check the ticket in the issue tracker for more info.
Calendar datatypes
Another important change in Elixir 1.3 is the addition of date related datatypes in the standard libraries. Until Elixir 1.2, we had two very good libraries for working with dates and times:
Thanks a lot to their authors for the great work. The biggest drawback, however, of not having these types in the standard library is the interoperability between libraries. If a library A uses timex while another library B uses calendar, it takes some work to make everything work smoothly together.
From Elixir 1.3, types to work will time and dates will be introduced in the standard library, and the libraries will therefore be using these types, which will make them interoperable for most common cases.
The types which will be introduced are:
CalendarDateTimeNaiveDateTimeDateTime
Calendar will contain typespecs for datetime related types, NaiveDateTime is a datetime without a timezone, and the other three types are what we could expect from the name.
An ISO8601 calendar implementation, with parsing and formatting functions is also available.
However, timezone manipulation and other calendar implementations are not the standard library so we will continue to rely on libraries for these.
You can check the relevant PR for more information.
Calendar datatypes sigils
Elixir 1.3 also includes handy sigils to create date and times
~D[2016-05-29]- builds a new date~T[08:00:00]and~T[08:00:00.285]- builds a new time (with different precisions)~N[2016-05-29 08:00:00]- builds a naive date time
Check the relevant commit or the docs for more information.
ExUnit new features
Two main new features has been added to ExUnit:
- The possibility to group tests together
- The possibility to compose tests better
The first one should be very familiar to most persons who have ever used
a BDD framework, it is the describe function, which allows to
group tests together. Here is the example from the documentation.
defmodule StringTest do
use ExUnit.Case, async: true
describe "String.capitalize/2" do
test "uppercases the first grapheme" do
assert "T" <> _ = String.capitalize("test")
end
test "lowercases the remaining graphemes" do
assert "Test" = String.capitalize("TEST")
end
end
end
This allow for example, to share the same setup for multiple tests.
The other great addition to ExUnit is the possibility to use atom in setups.
For example, until Elixir 1.2, we would have to write code as such:
defmodule UserManagementTest do
use ExUnit.Case, async: true
setup context do
user = log_user_in(context)
{:ok, user}
end
test "normal user", %{user: user} do
end
test "admin user", %{user: user} do
user = set_type_to_admin(user)
end
defp log_user_in(context) do
# ...
end
defp set_type_to_admin(user) do
# ...
end
end
With Elixir 1.3 grouping and composition, we can write something like this:
defmodule UserManagementTest do
use ExUnit.Case, async: true
describe "when user is logged in" do
setup [:log_user_in]
test ...
end
describe "when user is logged in and is an admin" do
setup [:log_user_in, :set_type_to_admin]
test ...
end
defp log_user_in(context) do
# ...
end
end
You can take a look at the thread in the ML for more information.
Access selectors
The access module now has very handy helpers which make working with nested hash a pleasure.
Here is the example from the docs
user = %{name: "john",
languages: [%{name: "elixir", type: :functional},
%{name: "c", type: :procedural}]}
update_in user, [:languages, Access.all(), :name], &String.upcase/1
This will upcase the name of all the languages.
The key helper is also very useful to deal with properties which
could be absent, for example, if we want to set the user name to a value
but we are not sure the user key is actually here, we could do something like
my_map = Poison.decode!(some_json)
put_in my_map, [Access.key("user", %{}), "name"], "some name"
and this will give the expected result regardless of the "user" key being already present
or not.
You can take a look at the initial proposition.
mix xref
Until Elixir 1.3, you could write something like this
defmodule Foo do
def foo(s) do
String.lengthh(s)
end
end
and the compiler would not tell you anything about it, from Elixir 1.3,
the new xref compiler has been added to mix default compilers, and
you now get a nice warning:
warning: function String.lengthh/1 is undefined or private
lib/foo.ex:3
xref also provides some information on module callers or dependencies.
Here is a graph generated with mix xref graph for one of my projects
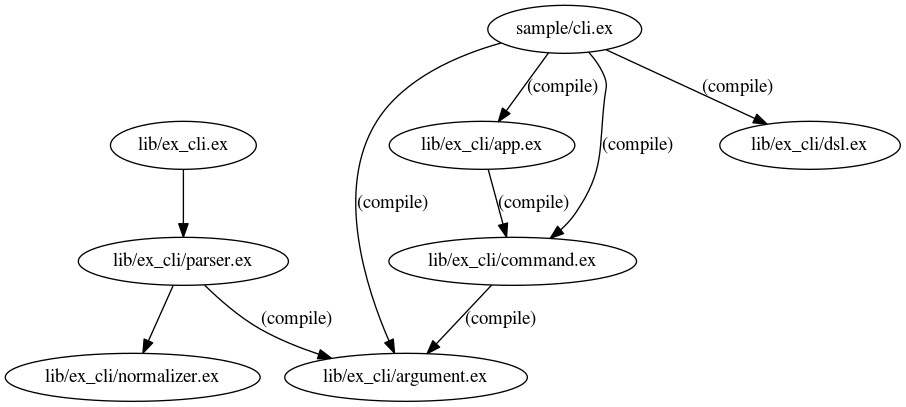
You can check this PR for more information.
mix test --stale
mix xref also allowed the mix test --stale functionality,
which only run the tests depending on the modules changed after
the last mix test --stale run. This will really help for long test
suites and allow TDD even better than before!
escript installation related tasks
As most of you probably already know escript are a very convenient way to distribute executables that can be run with only Erlang installed on the machine.
A CLI tool can be compiled by simply adding
escript: [main_module: MyApp.CLI]
to mix.exs project, as long as MyApp.CLI exports a main/1.
It is then only a matter of running mix escript.build to get a packaged executable.
This is perfect to distribute with attachments in GitHub releases for example.
With Elixir 1.3, we now have a way to install escripts from an URL, which makes
installing such binaries really trivial.
For example, to distribute an Elixir CLI tool, adding the following install instructions in the README will now be sufficient.
mix escript.install https://example.com/my-escript
There are also the mix escript to list the currently installed escripts, and mix escript.uninstall to uninstall an escript.
Although this may not seem such an important change, I think that having a unified way of installing and managing binaries is very helpful.
You can find more information in the relevant PR.
ExUnit diff
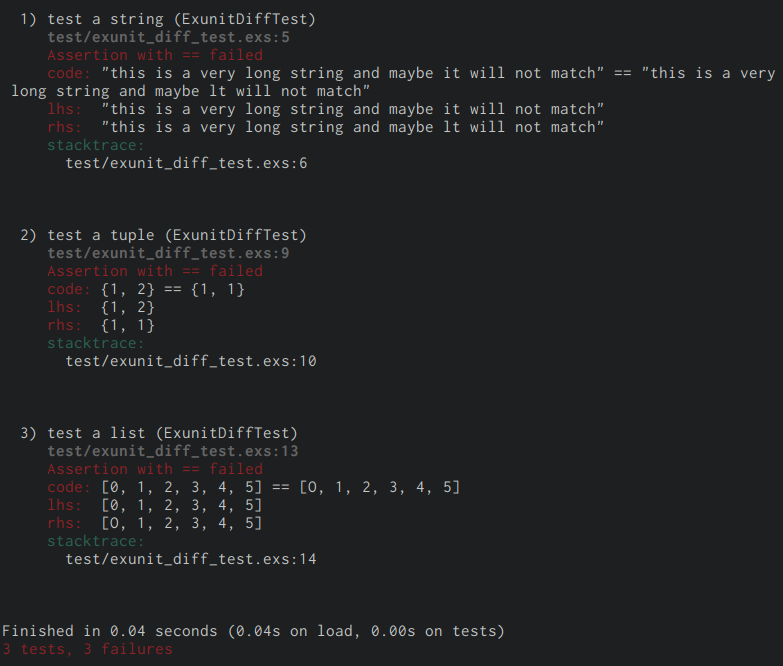
Until 1.2, when a test case failed, we had the expected output and the actual output, but no easy way to compare them. Elixir 1.3 introduces a very nice and easy to understand diff, which will probably save us a lot of time especially when working with large data structures or strings.
An image is worth a thousand words, so here we go:
Until Elixir 1.2
From Elixir 1.3
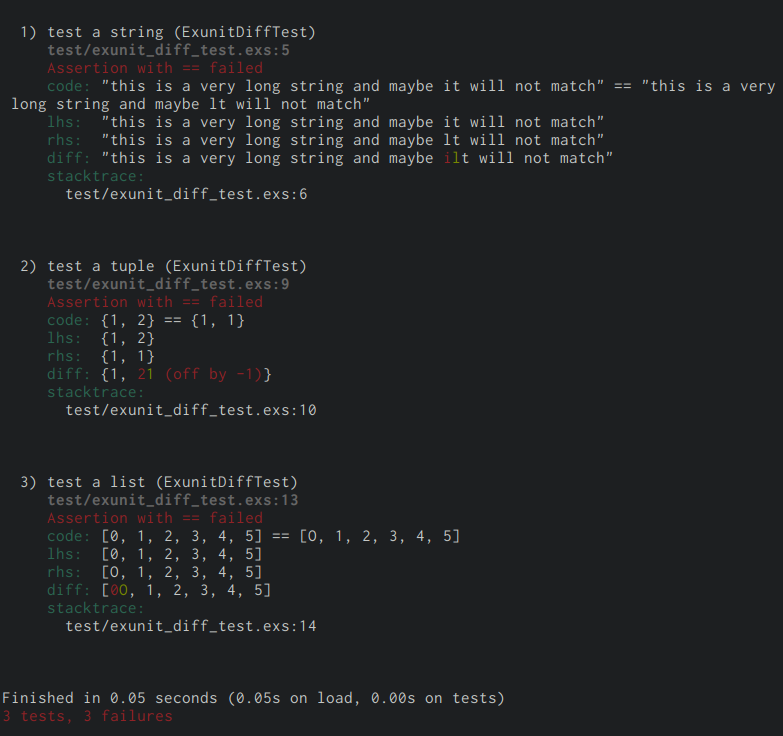
As you can see, a clean diff line has been added with a nice formatted diff.
For this addition, String.myers_difference/2 has been added to the String module.
iex(1)> String.myers_difference("foobar", "fopbar")
[eq: "fo", del: "o", ins: "p", eq: "bar"]
This improvement is divided in multiple PRs, but the largest part, including the diff algorithm implementation has been merged in this PR.
make compiler addition
Edit: this will finally be part of Elixir 1.4, and is available as a separate package for now.
Erlang, and by extension Elixir support Native Implemented Functions (NIFs), which is great for CPU intensive task, especially when immutability can make things slow.
A very good example usage of NIFs is the comeonin package, which provides the bcrypt and blowfish algorithms.
However, before Elixir 1.3, it was a little tedious to distribute a library containing NIFs, and for example comeonin had to write its own compiler to compile the NIFs.
As running make is a pretty common use case, Elixir 1.3 now integrates a make compiler, which can be used by simply adding :make under the :compilers key of the mix project.
It should also allow to customize the targets to run and the Makefile to use, but the feature has not been merged yet as I am writing this.
Changes in defdelegate
There has been a few changes in defdelegate. Let’s start by the “bad” news.
Using defdelegate with lists, and the :append_first option have been deprecated.
The following calls will therefore both receive a deprecation warning.
defdelegate [reverse(list), max(list)], to: :lists
# warning: passing a list to Kernel.defdelegate/2 is deprecated, please define each delegate separately
defdelegate map(list, callback), to: :lists, append_first: true
# warning: Kernel.defdelegate/2 :append_first option is deprecated
The reason for deprecating usage with lists is
You want each defdelegate to be on its own line so you can control module attributes like @doc
and the reason behind the deprecation of :append_first is that Elixir 1.3 will support optional parameters in defdelegate.
Until Elixir 1.2, given the following module
defmodule Hound.Helpers.Session do
def start_session(opts \\ []) do
# ...
end
end
if we wanted to use a delegate we had to write
def Hound do
defdelegate start_session, to: Hound.Helpers.Session
defdelegate start_session(opts), to: Hound.Helpers.Session
end
to support both the case where opts uses its default value and the case where we pass opts.
From Elixir 1.3, we will now be able to write
def Hound do
defdelegate start_session(opts \\ []), to: Hound.Helpers.Session
end
which will allow the delegate to have the same signature as the delegated function. For more info, you can check proposal for the optional parameters and the proposal the deprecations.
Process.sleep addition
Until Elixir 1.2, there was no Process.sleep but we could very easily achieve the same this by using :timer.sleep.
I believe the main reason Process.sleep/1 has been added to Elixir was to better document the fact that it is usually not a good idea to use it, but I could not find any releant information about why it was added in the mailing list.
Here are a few patterns where we should NOT use Process.sleep.
Waiting for a task to finish
We have Task.async and Task.await which is very clean when we want to do something asynchronously and wait for the result at some point.
do not
Task.start(fn -> do_something() end)
# wait until it's done
Process.sleep(10_000)
do
task = Task.async(fn -> do_something() end)
Task.await(task, 10_000)
We can also achieve something similar using a receive construct, which is actually what Task.await is using under the hood.
parent = self()
{:ok, pid} = Task.start fn ->
res = do_something()
send parent, {:result, res}
end
receive do
{:result, _res} -> :we_are_done
after
10_000 -> :timeout # we can use a timeout
end
Checking the state of a process
Another thing that should not be done using Process.sleep is waiting for a process to finish.
do not
{:ok, pid} = Task.start(fn -> do_something() end)
Process.sleep(10_000)
# monitoring
Process.alive?(pid)
but do
{:ok, pid} = Task.start(fn -> do_something() end)
ref = Process.monitor(pid)
receive do
{:DOWN, ^ref, _, _, _} -> :task_is_down
after
10_000 -> :timeout # optional timeout
end
When to use Process.sleep?
So, is there any case where it is relevant to use Process.sleep? Clearly it would not be here if there were not.
One of the case I use quite often is to wait before a retry, for example:
def execute(retries \\ 0)
def execute(0), do: do_execute()
def execute(n) do
case do_execute() do
{:ok, result} -> result
{:error, _err} ->
Process.sleep(5_000) # wait 5 secs before retrying
execute(n - 1)
end
end
def do_execute do
# do something that could fail
end
For more info, you can take a look at the relevant issue and the commit introducing Process.sleep/1.
Support of OTP optionalcallback
Erlang/OTP 18 has introduced the optional_callbacks attribute. Here is the description in the OTP changelog.
When implementing user-defined behaviours it is now possible to specify optional callback functions.
It is used to define a default implementation in a behaviour module, so that the modules implementing the behaviour can only keep the strict minimum.
This was already possible in Elixir, by using defoverridable/1.
Here is a short example.
defmodule MyBehaviour do
@callback required_callback :: any
@callback optional_callback :: any
defmacro __using__(_opts) do
quote do
@behaviour MyBehaviour
def optional_callback do
IO.puts("I am the default implementation")
end
defoverridable [optional_callback: 0]
end
end
end
defmodule ImplementingBehaviour do
use MyBehaviour
def required_callback do
IO.puts("I am the only one needed")
end
# but I can override `optional_callback` if I want
end
I therefore suppose the introduction of optionalcallback is to stay close to the Erlang/OTP implementation, which should I think make things simpler when working with Erlang behaviour directly.
The work on this one is still in progres, but you can check the relevant PR for more information.
New mix tasks
Elixir 1.3 also brings very neat mix tasks to get information about a project.
Until 1.2, we could use mix deps to show a project dependencies. This gave us an output like this:
* connection 1.0.2 (Hex package) (mix)
locked at 1.0.2 (connection)
ok
* fs 0.9.1 (Hex package) (rebar)
locked at 0.9.2 (fs)
ok
* gettext 0.11.0 (Hex package) (mix)
locked at 0.11.0 (gettext)
ok
* ranch 1.2.1 (Hex package) (rebar)
locked at 1.2.1 (ranch)
ok
* poolboy 1.5.1 (Hex package) (rebar)
locked at 1.5.1 (poolboy)
ok
....
which is enough to know what is installed, but does not tell us anything on why is package X or Y required.
Elixir 1.3 introduces mix deps.tree, which gives us a nice dependency tree:
foobar
├── gettext ~> 0.9 (Hex package)
├── cowboy ~> 1.0 (Hex package)
│ ├── cowlib ~> 1.0.0 (Hex package)
│ └── ranch ~> 1.0 (Hex package)
├── phoenix_html ~> 2.4 (Hex package)
│ └── plug ~> 0.13 or ~> 1.0 (Hex package)
│ └── cowboy ~> 1.0 (Hex package)
├── phoenix ~> 1.1.4 (Hex package)
│ ├── poison ~> 1.5 or ~> 2.0 (Hex package)
│ ├── plug ~> 1.0 (Hex package)
│ │ └── cowboy ~> 1.0 (Hex package)
│ └── cowboy ~> 1.0 (Hex package)
........
The other addition in 1.3 is app.tree.
Most applications will start other applications, and it can be handy to know who starts what.
At runtime, the :observer module can be used to get info about this, but the app.tree can now provide a quick overview without even having to run the app.
foobar
├── elixir
├── phoenix
│ ├── elixir
│ ├── plug
│ │ ├── elixir
│ │ ├── crypto
│ │ └── logger
│ │ └── elixir
│ ├── poison
│ │ └── elixir
│ ├── logger
│ │ └── elixir
│ └── eex
│ └── elixir
......
You can take a look at the deps.tree commit and the app.tree PR for more information.
Wrapping up
A lot of great stuff is coming in Elixir 1.3. I personally cannot wait to use the new features of with.
There are also a few things that got deprecated and will emit warnings, so I suggest you try to compile your project against Elixir master branch from times to times, this will probably save you some time later.
I am not sure if there is already a planned date for the release, but at the time I am writing this, there are only two issues opened in the 1.3 milestone, and a few PR that will probably be merged before we get to 1.3, so let’s hope we have a RC soon!
Edit: As of today (2016/6/21), Elixir 1.3 is now available!!
comments powered by Disqus